Came across two different network architectures that I think can discuss together as I feel that they share a similar core idea. Extract and leverage some global information from the data with global pooling.
PointNet
The objective of PointNet is to classify each voxel of a point cloud and detect the potential object described by the point cloud. Consequently, each voxel can belong to a different semantic class but they all share the same object class.
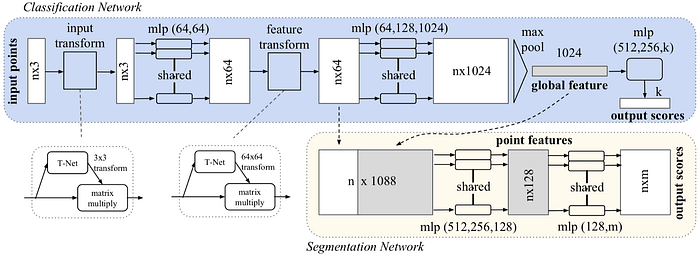
One important property of the point cloud is that all points are not in any particular order. Therefore, it does not make too much sense to train a convolutional layer or fully connected layer to intermix the point. The simplest reasonable operation to combine all information is just pooling (max or average). For PointNet, each point is first individually processed and then a global feature is generated using max pooling. The object described by the point cloud is also classified by the global feature.
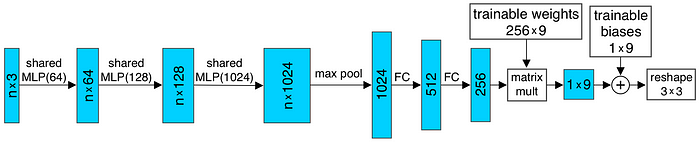
And the input transform and feature transform in the above figure are trainable and will be adapted to the input. This serves the purpose of aligning the point cloud before classification. For example, the T-Net in the input transform is elaborated as shown below.
To classify individual voxel, the global feature is combined with the local feature also generated earlier in the classification network. The combined feature of each voxel will be individually processed into point features, which are then used to classify the semantic class of the voxel.
SENet
SENet was the winner of the classification competition of ImageNet competition in 2017. It reduces the top-5 error rate to 2.251% from the prior 2.991%. The key contribution of SENet is the introduction of the SENet module as follows

The basic idea is very simple. For a feature tensor with $latex C$ channel, we want to adaptively adjust the contribution from each channel through training. Since there is no restriction in the order of the data inside the channel, the most rational thing to summarize that information is simply through pooling. For SE Net module, it is simply done with an average pooling (squeezing). The “squeezed” data are then used to estimate the contribution of each channel (different levels of “excitation”). The computed weights are then used to scale the values of each channel. This SE module can be applied in literally everywhere. For example, it can be combined with inception module to form SE-inception module or ResNet module to form SE-ResNet module as shown below.

