The idea of contrastive learning has been around for a while. It was introduced for unsupervised/semi-supervised learning. When we only have unlabelled data, we would like to train a representation that groups similar data together. The way to do that in contrastive learning is to introduce perturbation to a target sample to generate positive samples. The perturbations can be translation, rotation, etc. And then we can treat all other samples as negative samples. The goal is to introduce a contrastive loss that pushs negative samples away from the target sample and pull the positive samples towards the target sample.
Even for the case of supervised learning, the contrastive learning step can be used as a pre-training step to train the entire network (excluding the last classification layer). After the pretraining, we can train the last layer with labelled data while keeping all the other layers fixed.
The main innovation in this work is that rather than treating all other samples as negative samples. It treats data with the same labels as positive samples as well.
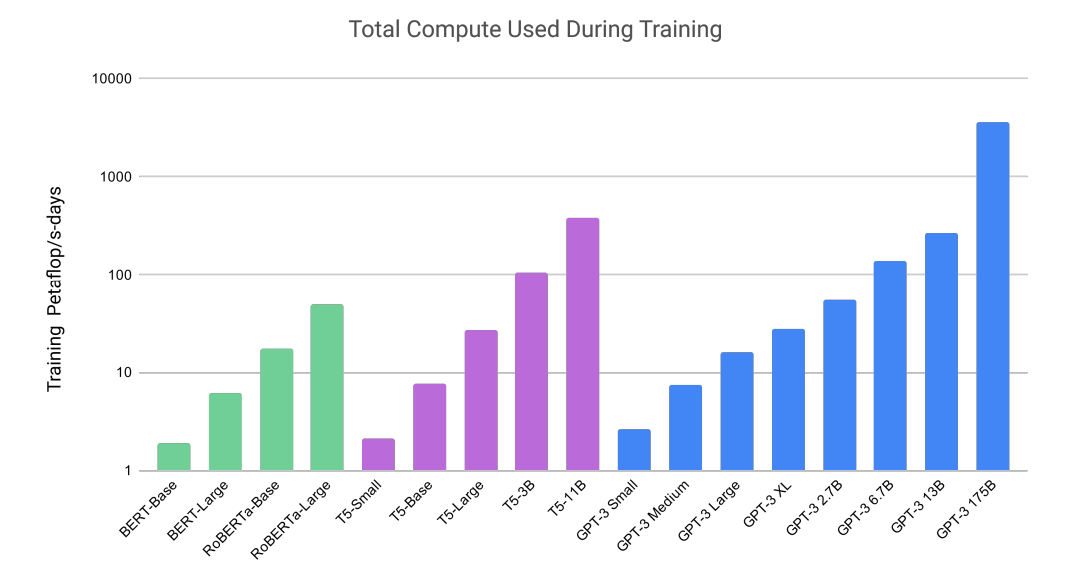
Ref: paper , video
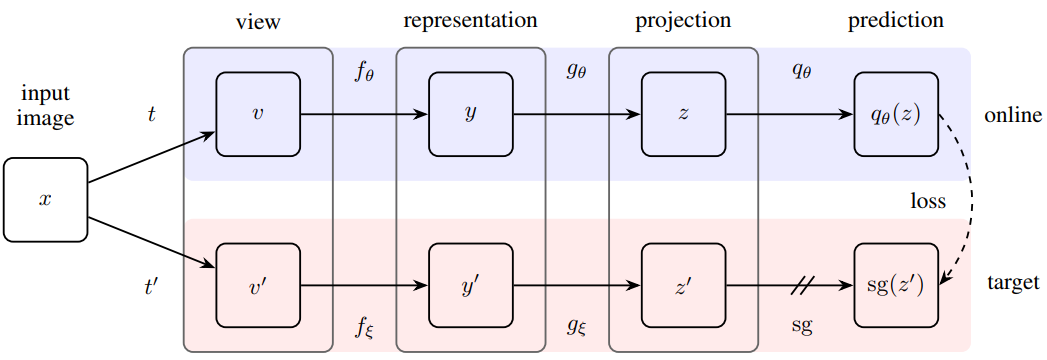
, video