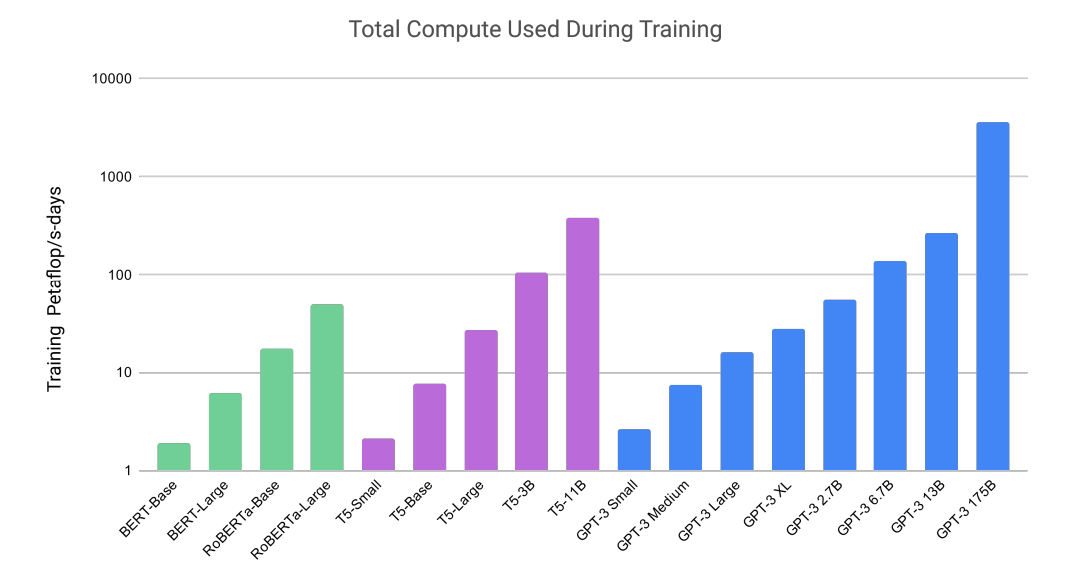
OpenAI released its latest language model. I found the training compute comparison facinating (~1000x BERT-base). The large model has 175B parameters. And some said it costed $5M to train. While it definiitely is impressive, I agree with Yannic that probably no “reasoning” is involved. It is very likely that the model “remembers” the data somehow and “recalls” the best matches from all training data.