KL divergence asymmetry pic.twitter.com/bvOAyCIMHw
— Ari Seff (@ari_seff) September 9, 2020
Month: September 2020
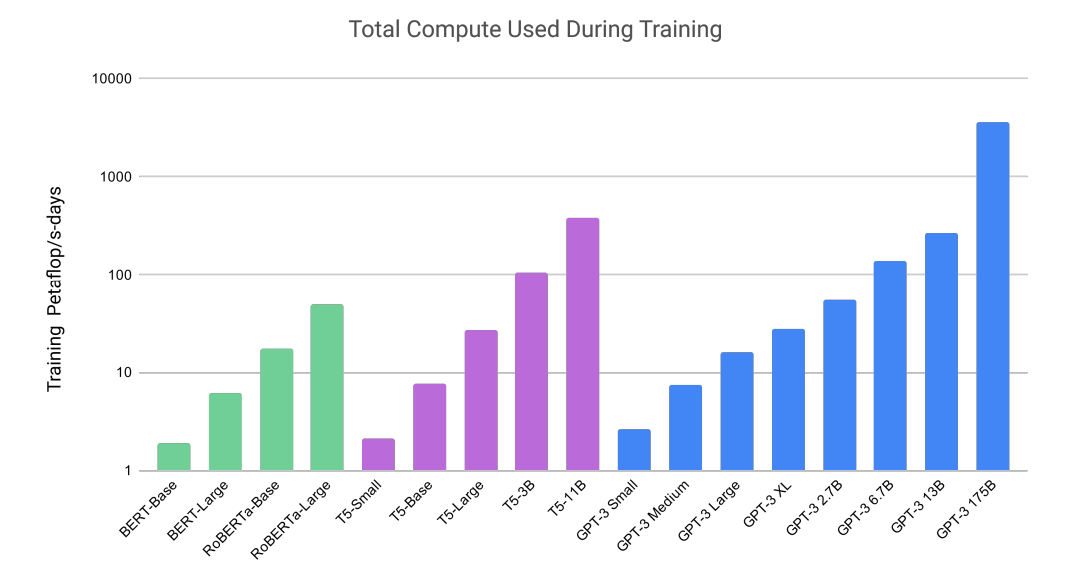
OpenAI released its latest language model. I found the training compute comparison facinating (~1000x BERT-base). The large model has 175B parameters. And some said it costed $5M to train. While it definiitely is impressive, I agree with Yannic that probably no “reasoning” is involved. It is very likely that the model “remembers” the data somehow and “recalls” the best matches from all training data.
The idea of contrastive learning has been around for a while. It was introduced for unsupervised/semi-supervised learning. When we only have unlabelled data, we would like to train a representation that groups similar data together. The way to do that in contrastive learning is to introduce perturbation to a target sample to generate positive samples. The perturbations can be translation, rotation, etc. And then we can treat all other samples as negative samples. The goal is to introduce a contrastive loss that pushs negative samples away from the target sample and pull the positive samples towards the target sample.
Even for the case of supervised learning, the contrastive learning step can be used as a pre-training step to train the entire network (excluding the last classification layer). After the pretraining, we can train the last layer with labelled data while keeping all the other layers fixed.
The main innovation in this work is that rather than treating all other samples as negative samples. It treats data with the same labels as positive samples as well.
Motivation
- Want to verify if someone has used your dataset for training
Idea
- Introduce extra (unreal) feature to data. For example, cat feature to cat image, dog feature to dog image
- Verify if dataset was used with hypothesis testing
Comments
- It seems that it is training and testing the same classifier. If a different classifier is used to the marked data, not sure if the method will actually work
- The “radioactive” images actually look very bad
- The idea does not seem to be new. And the execution is quite doubtful. It reminds me watermarking techniques popular in early 2000 but it never seems to take off since it doesn’t really work.