It is kind of mysterious that this works without using negative samples for self learning. See video and paper
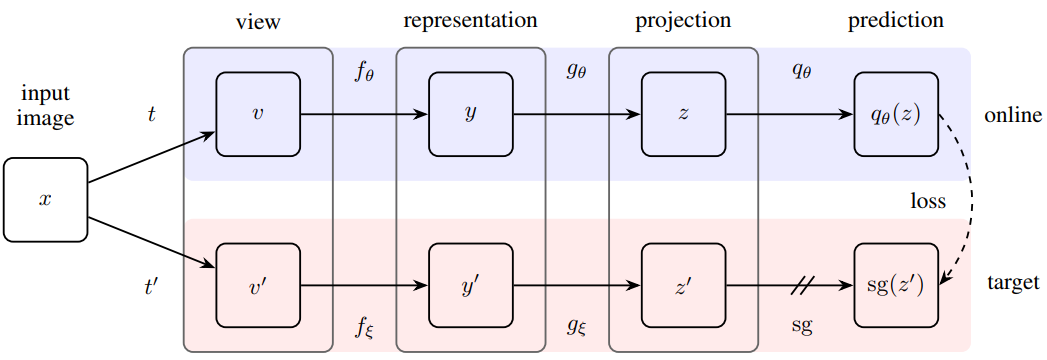
- The main idea is to train a representation network and a classifier so that the latter will predict the representation of an augmented data input.
- The representation network for the augmented data has moving average parameter of the current representation. Similar tricks have been used in deep reinforcement learning
- It is indeed quite surprising that this works without negative samples. Because there is nothing in the above model that avoids converging to trivial solution (everything maps to a constant)
- Experimental results look good. But also may not be accounted for too much. Their implementation for some older approaches have way higher prediction performance. And they pulled numbers from papers (reasonable tho) for comparison. Approach is probably on par and without negative samples, they can train with a smaller batch size
- They are using 512 TPUs for training for 7 hours…